

When can code that looks the same not be the same? When it's actually a Code Chameleon in disguise! Our failure to dig a little deeper and actually understand the code we were trying to rewrite led to a bunch of wasted time and effort.
Similar But Not Similar
In the process of rewriting an old app from ASP.NET WebForms to MVC (which I am thoroughly enjoying) we noticed that two pages in said app had a lot of data that looked very similar. Being the smart, capable programmers we think we are, we immediately started wondering if we could have those two pages share some markup so that we'd only have to write it once and use it lots of places. As far as we were concerned, it was a no-brainer to try to make these two pieces of markup reusable.
Take a look at these two (simplified) mockups, each of which approximate the kinds of data we were seeing:
Mockup 1

Mockup 2
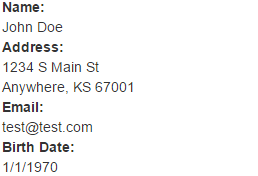
Those mockups are pretty similar, right? My team decided that, in the interest of code reuse, we would combine these two mockups into a single reusable partial view so that we could just plug it into each page where it was needed. We should reuse all the things, right?
Eh, not so much.
The first red flag that maybe reuse wasn't a good idea in this instance was when we discovered that the data we needed was coming from two different web services, and each of them structured it just a little differently. One returned a collection of Address objects, and the other returned just properties like StreetAddress, City, State, etc.
But no matter! We wanted reuse, and we were going to get it, consequences be damned!
Then, the second red flag was raised: the pages where this data was displayed used it differently from each other. One page wanted the data in a particular format, where the identifier ("Name:") was always displayed whether or not there was data to display as well. The other page didn't display the identifier if there was no associated data (e.g. don't display "Email:" if the user doesn't have an email address). Not only was the source of the data different, how it was displayed to the user was different as well.
Still, we intrepid (read: pigheaded) programmers pushed on, wanting desperately to achieve the nirvana of code reuse, even if just for this simple application.
Our hubris blinded us. After several hours of refactoring, cajoling, pleading, and finally demanding that the code give in to our wishes and magically become reusable, we gave up and began implementing completely separate views for each page. It was something we should have done much sooner than we did.
What we actually ended up doing was waste a lot of time and effort trying to force this data to fit together, because while it looked to be very similar, it was really quite different under the surface. We tried to create reuse where there was none to be had. The Code Chameleon we were fighting had fooled us and was now laughing at our arrogant, pitiful assumptions.

The Code Similarity Fallacy
In retrospect, the problem we had was twofold. First, we assumed that because the data we were using looked so similar, it would be structured similarly as well. Second, we stupidly continued trying to make this data "reusable" after it became apparent that this wasn't going to be the case.
What we should have done is dug a little deeper and realized that what looks similar on the surface often is different below. We fell victim to something I've started calling the Code Similarity Fallacy:
Just because two pieces of code look similar doesn't mean they should be combined into one reusable piece.
You can't force code to be reusable, and you always need to dig a little deeper to actually understand the code before you can start making assumptions about what it really does. If you look closer, you'll start to see the chameleons in your code, and you'll start to be able to tell what's actually similar, and what is just pretending to be.









