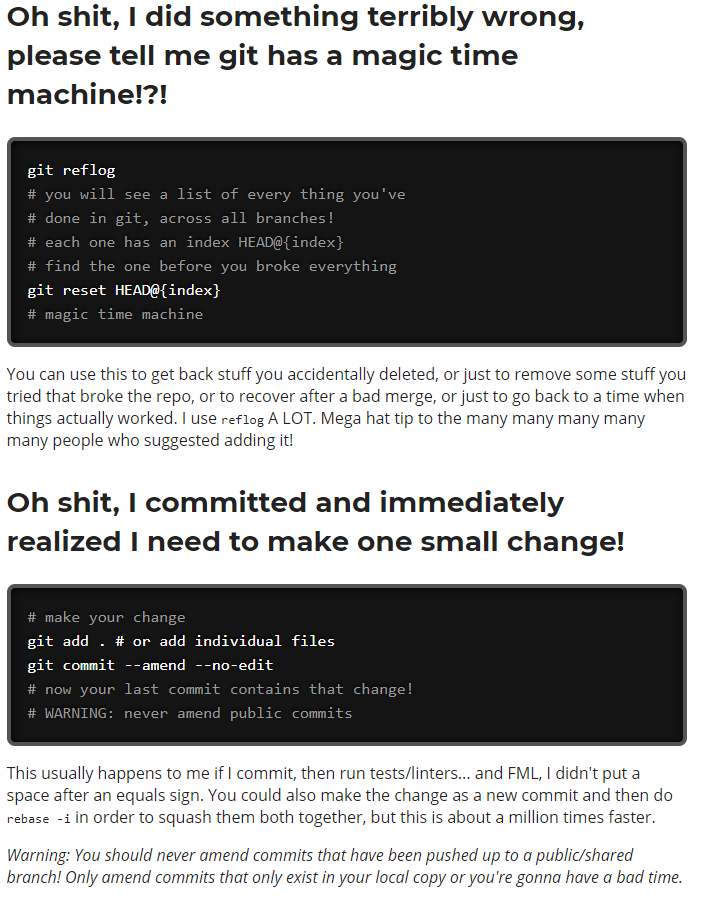
This isn't what I had planned for my first article, but it turned out to be the first article I needed to write.
We recently had an issue at work where a developer – without malice – went rogue and got several branches in a repository in a bad state. In this article I'll cover what happened, the technique I used to ultimately resolve the issue, and finally some thoughts on how to help prevent the issue from ever happening again.
If you have ever run into a similar case where a developer got in over his head with tooling, I'd love to hear about how you fixed it and any rules/policies you now have as a result. Sound off in the comments below.
The Background

I work for a private manufacturing company. As a 24/7 operation, we have several mission critical applications that we develop and support in-house. One of these is our primary plant floor system. This system began life roughly 12 years ago and is due for some pretty hefty refactoring that will have to be planned and made in fairly small chunks. Due to budgetary and business choices, development is way farther ahead with refactoring changes than our functional/QA team has had bandwidth to test and approve for release. We now have approximately 12 branches that represent incremental stages of a pretty major data layer refactor with no test/merge/install date set.
At the same time as that refactor is happening, we are also bringing online a new facility with our plant floor system which is taking all of our QA team's attention. This facility also required some customization from our team (approximately 50 man-days worth) and a business set deadline for go-live. In short, there's a lot of changes for this application that we're trying to manage at the moment. A lot more than we normally have, and a lot more than we really want.
The Event

One of our developers was on both the refactor project and the go-live project. His go-live changes included a set of data layer changes, and he decided to merge his changes into the staged refactoring branches while details were still fresh in his mind. Under normal circumstances, this would not be a bad thing. However, he didn't just merge his data layer changes. He merged all of the go-live related changes from a total of four developers. You can already surmise that all did not go well.
The details are still murky (and I don't even want to know), but somehow he ended up in a state were 6 commits needed to be undone from 6 of the staged refactoring branches. He asked for help from our team lead as to how to go about accomplishing that. The team lead said to revert each commit and if he didn't want to do that, he needed to talk to someone with more git experience.
The developer did not do this. Because he did not like the clutter in the history that results from reverting commits individually, he began researching other options. He found git-reset --hard. This command resets the branch to a previous commit; making it as if later commits never happened. This was exactly the behavior the developer wanted, so he used it. When he tried to push that change to our origin server, the repository rejected the push because rewriting history is not allowed by default. After some more searching, he found git push --force which allows a developer to overrule the objections of the repository. Each one of those commands have valid and necessary uses. However, combining them allows you to rewrite source control history; simultaneously destroying change tracking and giving other developers' cloned repositories an existential crisis. In our case, the developer used the combo on all 6 refactoring branches he touched. Only at this point did he realize that he was totally in over his head and came to me for help.
The Emotion

I won't lie, I was livid when I heard what he'd done. Not so much at the mistake itself; we all make those. What had me upset is that a) he'd done this without talking to someone else even though he was specifically told to do so, b) he did this to the repository for one of our largest, most mission critical systems, c) he did this 2 weeks before a major go-live when he didn't need to do it at all, and finally d) I was informed about this at 4 o'clock after a long day of fixing bugs in the same system.
I mention this because it is important that we as developers recognize that our emotional state directly affects our code and decisions we make. I cannot count the number of times I've put a hack in to get past a particularly frustrating problem, only to have that decision to come back to haunt me days, weeks, or even years later. When faced with something this serious, I've learned the hard way to recognize when I'm not in a good state for making decisions on my own and to vent some frustration, if I can, before tackling a fix.
In this case, I reviewed all of my decisions with my team lead. I even talked the situation over with a colleague to make sure that I wasn't totally off base just from being livid at the situation. Just doing these two things really helped to keep my head straight while we recovered from this situation.
The Clean up

Having worked as a developer for the better part of two decades, this was not the first mess I've had to clean up. (It wasn't even the first mess I needed to clean up this year, and it's only January.)
The first step was to stem the bleeding. I had the developer push their local branches that were in a "good" state to new branches in origin ( git push origin "old branch":"new branch" ). I also removed the force push permissions for everyone but the project administrators. We had enabled that option just to allow developers to clean up their own stale branches, so revoking the permission was fine for the short term at least. Then, I set a policy on the 6 remaining untouched refactor branches to require pull requests. At this point, I knew that no matter what, we wouldn't be any worse off than we were right then.
The next morning, after a cup of really good coffee, I was ready to tackle step 2 - assessing the damage. First I checked the new "from local" branches. They were all in the same state as the original branches, so I wasn't going to get miraculously lucky. All of the touched refactor branches were showing the same number (about 150) commits ahead of master. Prior to all of this, each refactor branch should have had roughly new 10 commits. (So branch A would be 10 commits ahead, branch B would be 20, and so on.) So, six of our 12 stages were wiped out. Branch 7 had all of the changes from the previous six, so the absolute worst case is that we would have a big change set to test/install before going back to more manageable chunks. At this point, I set a policy on the untouched refactor branches to require changes be done via pull request so that any mistakes I made during the recovery had at least somebody else sign off on as well.
Time for step 3: recovery. After researching options and several failed attempts at recovery, I had.... nothing. I was starting to feel like I wasn't going to be able to recover those branches. Then I found a part of Azure DevOps that I hadn't paid attention to before: the Pushes tab under Azure Repos. Azure DevOps keeps track of the who, what, and when of every push to every branch - including the last commit of the push. Success! For each refactor branch, I quickly went to the push prior to the troublemaker, created a new branch, and set a PR policy on it. Soon, all 6 refactor branches were recovered to before the troublesome merge.
What I was dreading to be a multi-day recovery took about 3 hours total.
The Aftermath and Future

Due to our workload, we still haven't done a complete retrospective. (Its on the agenda for our next project meeting.) Even without that, there are some issues and permanent changes we have under consideration.
- Do we ever re-enable force push for this (or any) repository?
As long as deleting a branch requires a force push permission, there will be this debate on my development team. The current thoughts are that on certain production critical systems, force push will remain disabled and project admins will be tasked with helping clean up stale branches - any branch without commits ahead of master will be subject to deletion.
Our other repositories have one, maybe two developers. Since the project admins would effectively be those same developers, we'll enable force push rather than grant full admin rights.
- Any "long-lived" branch in a repository MUST* require pull requests to make changes.
A working definition for long-lived branches in my organization would be any branch that won't be merged in the next 2 months. * We will probably make some exceptions for smaller repositories due to a few obstinate developers, but it's not going to be optional for something used across multiple divisions with more than 2 developers.
- More git training and review
Most of my developers have used centralized source control for the majority of their careers. When we transitioned to git there wasn't a lot of time devoted to training, so the training we did focused on the concept of a distributed source control system and the everyday commands they'd need. As a result, they are not as familiar with some git commands and concepts like git reset, git push --force, and git rebase. This event brought to light that we should create a basic git training plan and an advanced git training plan. The goal being to point out that if you are about to go outside of normal operating command sets, you really need to get someone else involved as well.
That's my tale of one developer getting in over their head and how close a mistake can come to adversely effecting an entire company. I and my team have already moved on to the next scheduled emergency, but each day we learn and try to do better. Hopefully our experience will help someone else do better too.